Clickhouse 索引优化
前言
当前计划将报价数据从 mongodb 转用 clickhouse 存储,插入模拟数据 2.54 亿条(254615855),使用代码分段查询同步数据时,发现查询到百万行的时候,查询效率非常低,猜想其原因可能是查询时未使用到索引。
1. 还原现场
以下 SQL 语句中进行了脱敏,字段名称、字段类型及表结构均与公司中所用不同,但根据数据特征创建的这个表,是符合本文所描述的。
创建数据库:
CREATE DATABASE IF NOT EXISTS price_data ON CLUSTER ck_cluster ENGINE = Atomic COMMENT '报价数据';
当前创建表的 DDL 语句为:
CREATE TABLE IF NOT EXISTS market_price ON CLUSTER ck_cluster
(
`exchange` String COMMENT '交易所',
`symbol` String COMMENT '品种',
`broker` String COMMENT '经纪商',
`price` Float64 COMMENT '报价',
`ts` Int64 COMMENT '报价时间戳(纳秒值)',
`remark` String COMMENT '备注',
`date` Date COMMENT '分区键'
)
ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/price_data.market_price','{replica}')
PARTITION BY toYYYYMMDD(date)
ORDER BY (symbol,broker)
SETTINGS index_granularity = 8192
COMMENT '报价数据';
其中 ORDER BY 子句是必须指定的,未特殊指定 PRIMARY KEY 时,则默认 ORDER BY 子句中定义的列即为 PRIMARY KEY 的列。
插入 N 条测试数据:
INSERT into market_price(*) values ('NASDK','APPLE','Intrade',3.1415926,1675825155460811147,'',today());
查询语句:
SELECT * FROM `market_price` WHERE date = '2023-02-07' and ts > 1675825155460811147 ORDER BY ts asc LIMIT 2000;
该条语句查询出的结果集,位置偏移表中首行记录几百万,查询耗时 14.331s,这是无法接受的。
我们查看它使用到的索引情况:
EXPLAIN indexes = 1
SELECT * FROM `price_quotes` WHERE date = '2023-02-07' and ts > 1675825155460811147 ORDER BY ts asc LIMIT 2000;
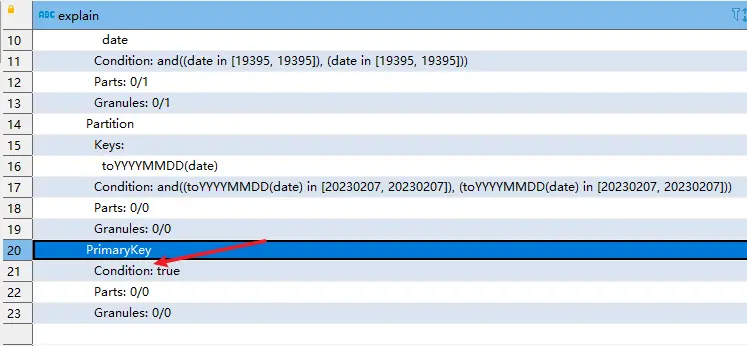 查询计划显示,该条语句并未使用到索引。
查询计划显示,该条语句并未使用到索引。
由上文可知,该表在创建时,隐式创建的主键索引是 PRIMARY KEY(symbol,broker),若将上条 SQL 查询的结果集中第一条的 symbol 和 broker 获取到,作为查询条件,得到如下 SQL:
SELECT * FROM `market_price` WHERE symbol = 'APPLE' AND broker = 'Intrade' AND date = '2023-02-07' and ts > 1675825155460811147 ORDER BY ts asc LIMIT 2000;
查询耗时 142ms,结果很理想。
我们查看它使用到的索引情况:
EXPLAIN indexes = 1
SELECT * FROM `market_price` WHERE symbol = 'APPLE' AND broker = 'Intrade' AND date = '2023-02-07' and ts > 1675825155460811147 ORDER BY ts asc LIMIT 2000;
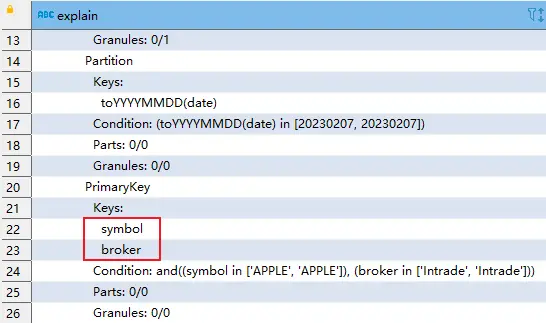 查询计划显示,该条语句使用到了 PRIMARY KEY 中定义的两个列。
查询计划显示,该条语句使用到了 PRIMARY KEY 中定义的两个列。
至此,验证了我们的猜想,查询效率低就是没有用到索引。
2. 解决问题
但是 clickhouse 中的索引具体该如何创建和使用,有什么规则和特点,对于优化我们的表是至关重要的,因此查阅 clickhouse 官方文档后,得到一些结论,在某些方面,我会与传统数据库(MYSQL)做对比。
首先,clickhouse 与 mysql 在索引方面最大的一点不同是:mysql 的B+数索引会为每行数据创建一个索引;clickhouse 则使用跳数索引,它并不会为每行数据都创建索引,而是将数据分粒度(granularity),每个粒度创建一个索引。
建表时,如未显示指定,则 clickhouse 会自动加上 SETTINGS index_granularity = 8192,也就是说默认的索引粒度(或者叫粒度大小)为 8192。假设一个表中有 16384 行数据,则会创建两个索引,在本表中,有 254615855 行,则理论上会创建 254615855 / 8192 ≈ 31082(向上取整) 个索引。
这一点,可以通过如下语句查看:
SELECT
part_type,
path,
formatReadableQuantity(rows) AS rows,
formatReadableSize(data_uncompressed_bytes) AS data_uncompressed_bytes,
formatReadableSize(data_compressed_bytes) AS data_compressed_bytes,
formatReadableSize(primary_key_bytes_in_memory) AS primary_key_bytes_in_memory,
marks,
formatReadableSize(bytes_on_disk) AS bytes_on_disk
FROM system.parts
WHERE (table = 'market_price') AND (active = 1)
FORMAT Vertical;
为什么上面会说理论上呢?因为我们在建表时除了可指定索引粒度外,还可以指定索引粒度字节:index_granularity_bytes = 0(表示禁用自适应索引粒度字节)。同时指定时:SETTINGS index_granularity = 8192, index_granularity_bytes = 0; 。
clickhouse 默认的索引粒度字节为 10MB,若未禁用自适应索引粒度字节时(即默认情况下),当符合以下两个任一种情况,则会创建一个索引粒度:
- n 行数据的字节数量 >= 10MB,则这 n 行数据作为一个索引粒度。将此粒度中的第一行数据作为索引;
- n 行数据的字节数量 < 10MB,但 n = 8192,则这 n 行数据作为一个索引粒度。将此粒度中的第一行数据作为索引;
当每行数据的字节非常大时,可能未达到 8192 行即创建一个索引,因此索引数可能会更多。
对于 clickhouse 索引优化,总结出如下几点:
- clickhouse 的索引同样遵循左前缀原则,因此查询条件的顺序要与主键索引定义的顺序相同,这个规则和 mysql 是一样的。但和 mysql 不同是,mysql 除了拥有主键索引外,还可以对其他列创建索引,或对多个列创建复合索引;而 clickhouse 一般只创建主键索引就够了,因此,如无特别说明,下文中所述的“索引”一律指“主键索引”。
- clickhouse 建表要求必须指定排序键(ORDER BY),主键索引(PRIMARY KEY) 为可选项。如果显示指定主键索引时,则需要遵循一个原则:主键索引中指定的列必须是排序键的前缀。例如,指定了 ORDER BY (core_sym_id,maker_sym_id,maker_id),则主键索引可能为:PRIMARY KEY (core_sym_id,maker_sym_id) 或 PRIMARY KEY (core_sym_id),不可为:PRIMARY KEY(date),因为 date 不存在 ORDER BY 指定的列中。
- 在一列数据中,相似的数据彼此靠近,则可以被更好的压缩。数据越相似,压缩效率越好。因此合理指定 ORDER BY 很重要,当我们指定 ORDER BY (core_sym_id,maker_sym_id,maker_id) 时,数据会依次按照 core_sym_id,maker_sym_id,maker_id 的升序存储在磁盘上。
- 当查询的列是复合索引键的第一个列时,如:PRIMARY KEY (core_sym_id,maker_sym_id),当查询条件为 core_sym_id= ?。此时,会采用二分搜索,查询效率高;当查询条件为 core_sym_id= ? and maker_sym_id = ?,则会先使用 core_sym_id= ? 这个条件进行二分搜索,然后对查询到的结果进行 maker_sym_id = ? 条件做排除;若查询条件仅为 maker_sym_id = ?,则此时会直接使用排除搜索的方式进行查找,查询效率取决于索引第一个列值的重复基数,最坏的情况下会造成全表扫描。
- 复合主键索引中,列的顺序非常重要,按照基数升序有利于提高次键的查询效率。前置键有较低的基数时,有利于后置键的查询效率,因此尽量为重复值多的列创建索引。—— 注:列基数低,表示该列的数据重复多;列基数高,表示该列的数据重复少
- 当复合索引中多个列有相似的基数时(即重复情况差不多,可以通过查询该列值去重后的行数来比较),为复合索引的第二个列额外创建索引,并不会对查询效率带来多少提升。—— 注:列创建索引语句见 附1
- 当有直接查询复合索引中第二个列时,通常是使用多个主键索引的方式来解决。使用多个主键索引的方式有 3 种:创建第二张表,使用不同的主键顺序,缺点是当向原表插入数据时,需要手动将第一张表中的数据同步到第二张表,并且查询时也要指定查询第二张表;在原表上创建实体化视图,当向原表插入数据时,会自动将数据同步到视图中,缺点是查询时依然要指定查询视图表;向原表添加投影,类似于第二种方式,当向原表插入数据时,会自动将数据同步到投影表中,并且投影表是隐藏的,查询时只需指定查询原表,clickhouse 会自动根据条件来选择查询原表还是投影表,缺点未知,文档中没有提及。—— 注:创建投影语句见 附2
- 对于复合主键索引中,多个列有相似的基数时,按需只保留第一个列(相似基数的其他列,写了没有作用,反而会增加索引的内存消耗),有助于减少索引的内存消耗。而对于相似基数的其他列查询需求,应当使用多主键索引来代替,推荐使用上面提到的投影表。
- 在复合主键索引中,定义的列顺序会对次列的查询效率以及表数据压缩有非常显著的影响。若复合主键索引的多个列基数差异非常大,则按照基数升序对查询速度和数据压缩效率是有利的,且这些列的基数差异越大,影响越大。
- 若需要快速定位到单个行,可以为表设置一个 uuid 列,为达到最快的定位速度 uuid 列必须是复合主键索引列中的第一个。上面我们提到 clickhouse 的数据是按照复合主键索引列中定义的顺序存储在磁盘上的,uuid 列值不重复,势必基数非常高,若在复合主键索引中,uuid 列排在其他基数低地列之前,将会严重影响次键的查询速度以及数据的压缩率。通常在检索速度和压缩率之间的折衷选择是在使用复合主键索引时,将 uuid 列置于索引列中的最后一位。
综上,可以看出在提升查询速度方面, clickhouse 与 mysql 的索引创建有很大的差异:mysql 是尽量为重复数据少地列创建索引;clickhouse 是尽量为重复数据多的列创建索引。mysql 除了拥有主键索引外,还可以对其他列创建索引,或对多个列创建复合索引;而 clickhouse 一般只创建主键索引就够了。
附1:
ALTER TABLE market_price ADD INDEX broker_skipping_index broker TYPE minmax GRANULARITY 8192;
ALTER TABLE market_price MATERIALIZE INDEX broker_skipping_index;
附2:
// 创建投影
ALTER TABLE market_price
ADD PROJECTION hits_market_price_broker
(
SELECT *
ORDER BY (broker, symbol)
);
// 填充数据
ALTER TABLE market_price
MATERIALIZE PROJECTION hits_market_price_broker;
3. 优化建表
综上所述,结合报价表的特点,优化后的建表语句如下:
CREATE TABLE IF NOT EXISTS market_price
(
`exchange` String COMMENT '交易所',
`symbol` String COMMENT '品种',
`broker` String COMMENT '经纪商',
`price` Float64 COMMENT '报价',
`ts` Int64 COMMENT '报价时间戳(纳秒值)',
`remark` String COMMENT '备注',
`date` Date COMMENT '分区键'
)
ENGINE = MergeTree()
PARTITION BY toYYYYMMDD(date)
ORDER BY (exchange,broker,symbol,ts)
SETTINGS index_granularity = 8192
COMMENT '报价数据';
查询数据压缩率:
SELECT
table AS `表名`,
sum(rows) AS `总行数`,
formatReadableSize(sum(data_uncompressed_bytes)) AS `原始大小`,
formatReadableSize(sum(data_compressed_bytes)) AS `压缩大小`,
round((sum(data_compressed_bytes) / sum(data_uncompressed_bytes)) * 100, 0) AS `压缩率`
FROM system.parts
WHERE table IN ('market_price')
GROUP BY table;
写入数据后可执行:
OPTIMIZE TABLE market_price FINAL;
删除表:
drop table market_price on cluster ck_cluster;
查看集群信息:
select * from system.clusters;
如果查询依然不够理想,可以考虑修改 SQL,不使用 ts 作为条件,或者创建投影,但投影表会带来什么影响,文档未提及,目前未知。
4. 执行计划
ClickHouse在版本20.6.3之后支持explain查看执行计划。explain基本语法如下:
EXPLAIN [AST | SYNTAX | PLAN | PIPELINE] [setting = value, ...] SELECT ... [FORMAT ...]
- AST: 用于查看语法树。
- SYNTAX: 用于查询 ClickHouse 优化后的语法。
- PLAN: 用于查看执行计划,默认值。
- PIPELINE: 用于查看 PIPELINE 计划,相对于 PLAN 更加详细。
例如,查看语法树:
EXPLAIN AST SELECT id,name,age FROM user;
查看优化后的语法(比较常用):
EXPLAIN SYNTAX SELECT t.id,t.name FROM (SEELCT id,name FROM user) t WHERE t.id <3;
在使用PLAN时有一些设置:
- header: 打印计划中各个步骤的输出头,默认关闭,默认值0。
- description: 打印计划中各个步骤的描述,默认开启,默认值1。
- indexes: 打印计划中使用的索引,默认关闭,默认值0,支持 MergeTree 表引擎。
- actions: 打印计划中各个步骤的详细信息,默认关闭,默认值 0。
- json: 打印计划步骤时使用 json 格式展示,默认关闭,默认值 0,建议使用默认 TSVRaw 格式,避免不必要的开销。
设置一些值后的查询,例如:
EXPLAIN PLAN header=1,description=1,indexes=1,actions=1,json=1 SELECT id,name,age FROM user;
关于 json 中详细的字段解释可以参照官网解释。
在执行 pipeline 是也可以设置一些参数:
- header: 打印计划中各个步骤的输出头,默认关闭,默认值 0。
- graph: 使用 DOT 图形语言描述管道图,默认关闭,默认值 0。
- compact: 如果 graph 开启,以紧凑模式打印管道图,默认开启,默认值 1。
EXPLAIN PIPELINE header=1 SELECT name,count() FROM user GROUP BY name;
结语
在进行海量数据迁移、导出等场景时,读取原库数据优先考虑使用流式查询,在内存中将数据分段写入目标库。
而此处,流式读取 clickhouse 时需要注意,设置 max_execution_time=0,这个设置表示语句最大的执行时间,设置 0 表示不限制。因为流式查询时,数据库连接会开启很久,如果这里不去掉限制,则在超出时间后会自动断开连接。